Watch what happens.
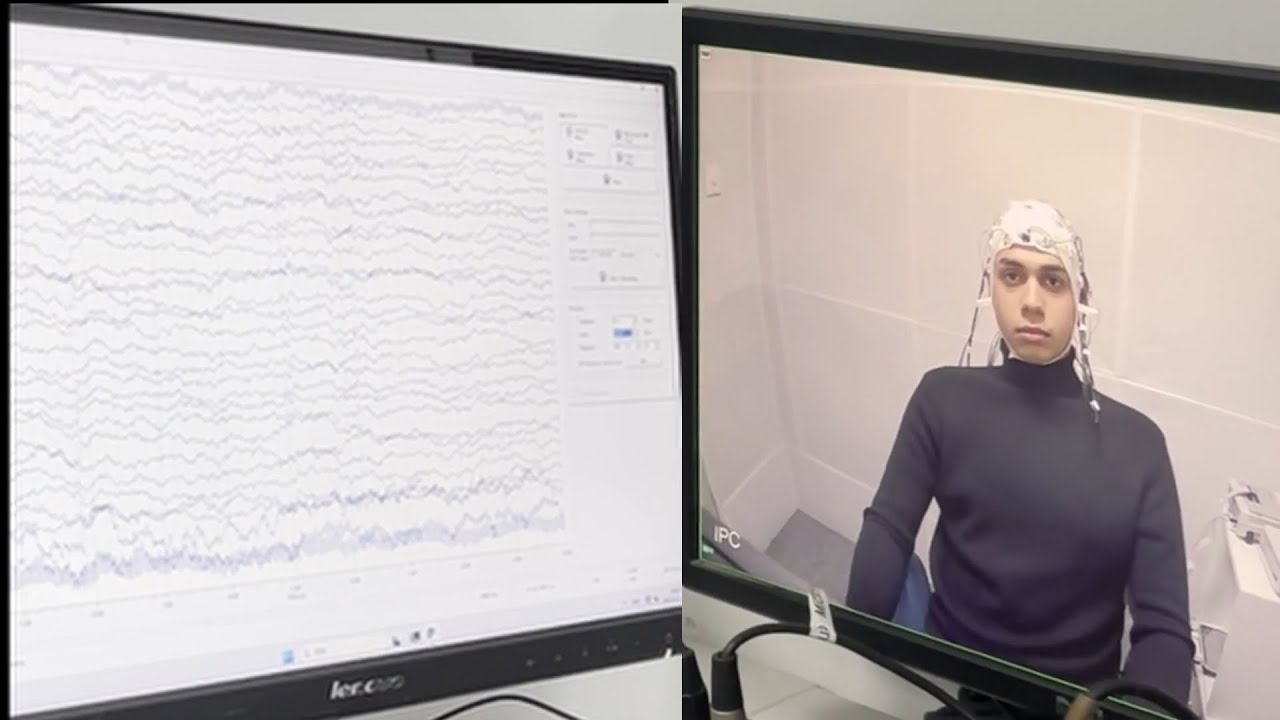
Real EEG signal. Real imagined sentences. The system is running on actual brain data — not synthetically generated, not reconstructed from text. Imagined speech neural activity patterns, decoded by the model.
Dataset: ChiSCO — the only large-scale published sentence-level imagined speech dataset · 23,000 recordings · Scientific Data, Nature 2024
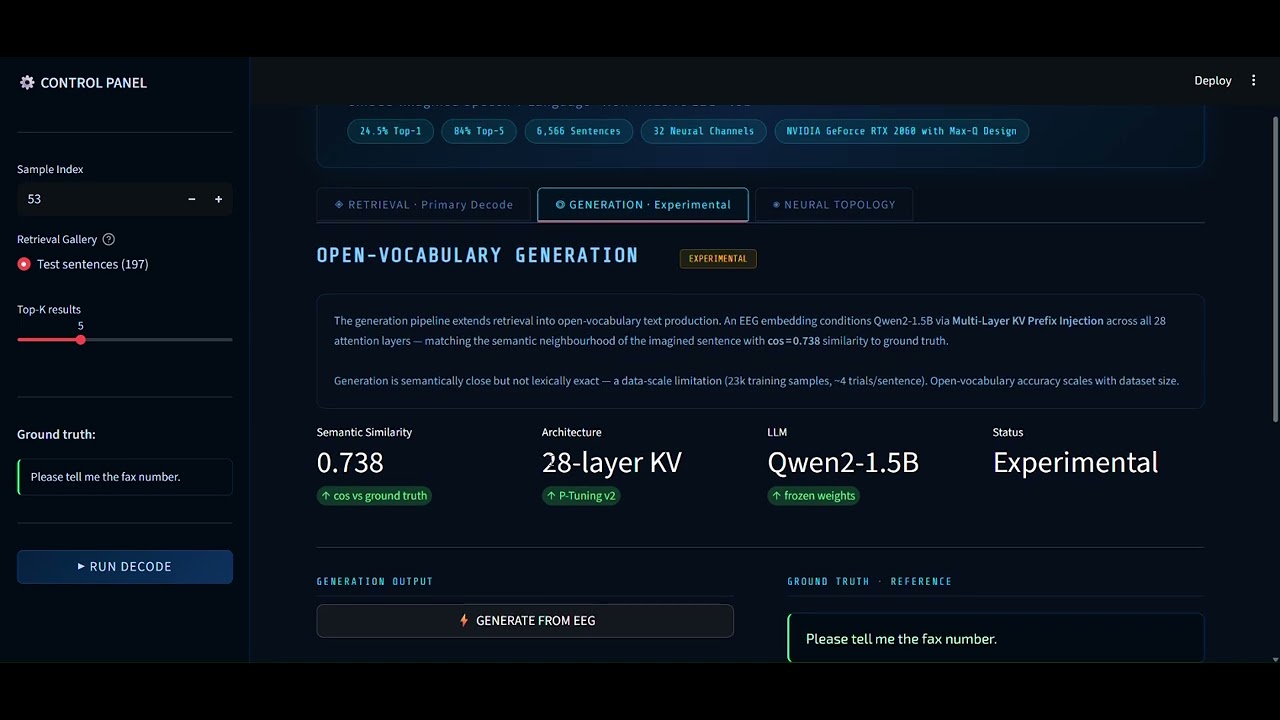
The system decoded what they were thinking. 84% of the time, in the top 5 guesses. 24.5% exact match. From imagined sentences. No speaking. No movement. No benchmark existed for this task — in research or industry — before we built one.
84% on 197 sentences is not a research result awaiting productization. AAC research shows 100–200 core phrases cover 80% of daily communication needs. Our 197-sentence corpus was not chosen arbitrarily — it is aligned with thirty years of AAC research. The number is not a research constraint. It is the right number for the first product. The right vocabulary, reliably decoded — gives a fully locked-in patient the ability to communicate pain, need, love, goodbye. That product does not exist today without surgery. It exists now. And as the system learns each individual's EEG patterns over time, Top-5 becomes Top-1 for that person. The first guess is right. Every time.

